Python爬虫:有道翻译接口获取翻译结果 |
您所在的位置:网站首页 › 数据解析 翻译 › Python爬虫:有道翻译接口获取翻译结果 |
Python爬虫:有道翻译接口获取翻译结果
|
之前写了篇获取百度翻译接口的文章,今天再拿有道翻译练练~适合爬虫新手练习。 目标:获取有道翻译结果 工具:chrome/firefox浏览器、pycharm、python3.7 模块:requests、time、random、string、hashlib 分析:打开浏览器鼠标右键检查(或者按F12)开始分析页面特点,发现和百度翻译一样,左边窗口输入翻译原文,会自动检测语言并在右边窗口会给出翻译结果,页面没有刷新,那么应该也是ajax请求的,筛选XHR找一找看看,只有一个请求,切到response发现就是翻译接口,ok,那么直接请求这个接口应该能拿到翻译结果,接下来分析参数; i:翻译原文 from:原文语言 (这个参数可以填AUTO,自动检测) to:翻译语言 (这个参数可以填AUTO,自动检测) smartresult:固定值 client:固定值 salt:这个值应该是下面的lts加一位数字,有待验证 sign:服务器签名验证 lts:根据经验初步观察应该是时间戳,后面验证看看 bv:暂时未知(相同浏览器刷新页面不会变化,换浏览器后会变) doctype:固定值 version:固定值 keyfrom:固定值 action:翻译类型(两种类型,当手动切换语言的时候这个参数是lan-select,自动检测语言的时候是FY_BY_REALTlME)
salt:时间戳+1位随机数,这个随机数使用random和sting模块就行,string.digits数字0-9,random.sample从中随机取一位数字,最后和时间戳组合起来 salt = str(lts) + ''.join(random.sample(string.digits, 1))sign:先组合字符串,再利用hashlib模块的MD5方法进行加密 # 组合字符串 sign_string = 'fanyideskweb{word}{time}]BjuETDhU)zqSxf-=B#7m'.format(word=keyword, salt=salt) # 加密 hash = hashlib.md5() hash.update(sign_string.encode()) sign = hash.hexdigest() 完整代码: import requests import time import random import string import hashlib class FanYi: def __init__(self, keyword): self.keyword = keyword self.url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'referer': 'http://fanyi.youdao.com/', 'cookie': '[email protected]' } def form_data(self): # 时间戳 lts = int(time.time() * 1000) # 时间戳+1位随机数 salt = str(lts) + ''.join(random.sample(string.digits, 1)) # 组合字符串 sign_string = 'fanyideskweb{word}{salt}]BjuETDhU)zqSxf-=B#7m'.format(word=self.keyword, salt=salt) # 加密 hash = hashlib.md5() hash.update(sign_string.encode()) sign = hash.hexdigest() data = { 'i': self.keyword, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', 'salt': salt, 'sign': sign, 'lts': lts, 'bv': '02edb5d6c6ac4286cd4393133e5aab14', 'doctype': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_REALTlME' } return data def run(self): form_data = self.form_data() response = requests.post(self.url, headers=self.headers, data=form_data).json() result = response['translateResult'][0][0]['tgt'] print('翻译结果:', result) if __name__ == '__main__': word = input('请输入原文: ') fy = FanYi(word) fy.run()遇到问题:需要注意有道的反爬,如果不带referer和cookie会请求不到数据,cookie只需要带一个搜索用户id的参数,从浏览器复制就行,这个参数有效时间挺长的,都相当于长期有效了。 总结:有道翻译js加密代码比较容易,没有百度翻译加密那么复杂,简简单单适合新手练习~ 所有代码 |
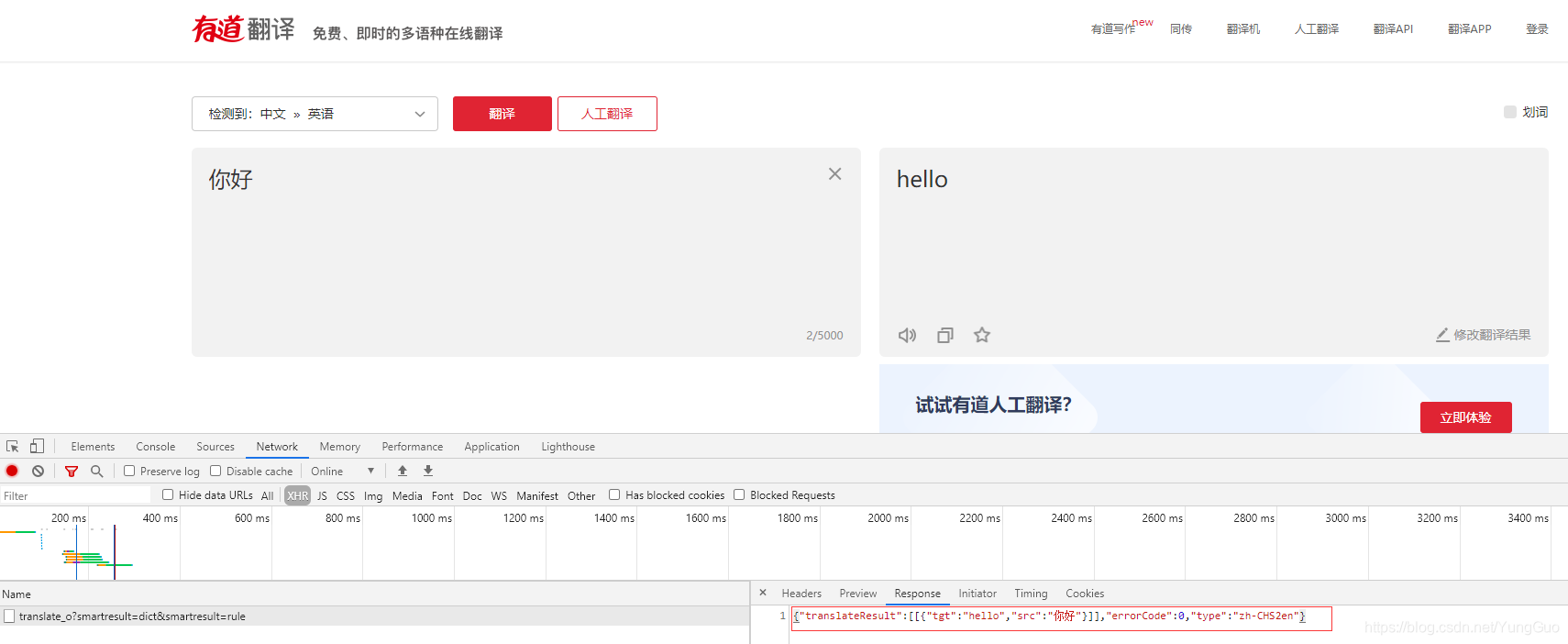 切到headers看看传递了什么参数,参数比较多,接下来分析下13个参数。我一般对参数初步分析就是多次刷新或更换浏览器观察参数变化情况,从经验上来看,一般这种大网站请求参数都会有加密参数,有些参数直接复制使用是没办法拿到数据的,这里初步分析具体过程就不写了;
切到headers看看传递了什么参数,参数比较多,接下来分析下13个参数。我一般对参数初步分析就是多次刷新或更换浏览器观察参数变化情况,从经验上来看,一般这种大网站请求参数都会有加密参数,有些参数直接复制使用是没办法拿到数据的,这里初步分析具体过程就不写了;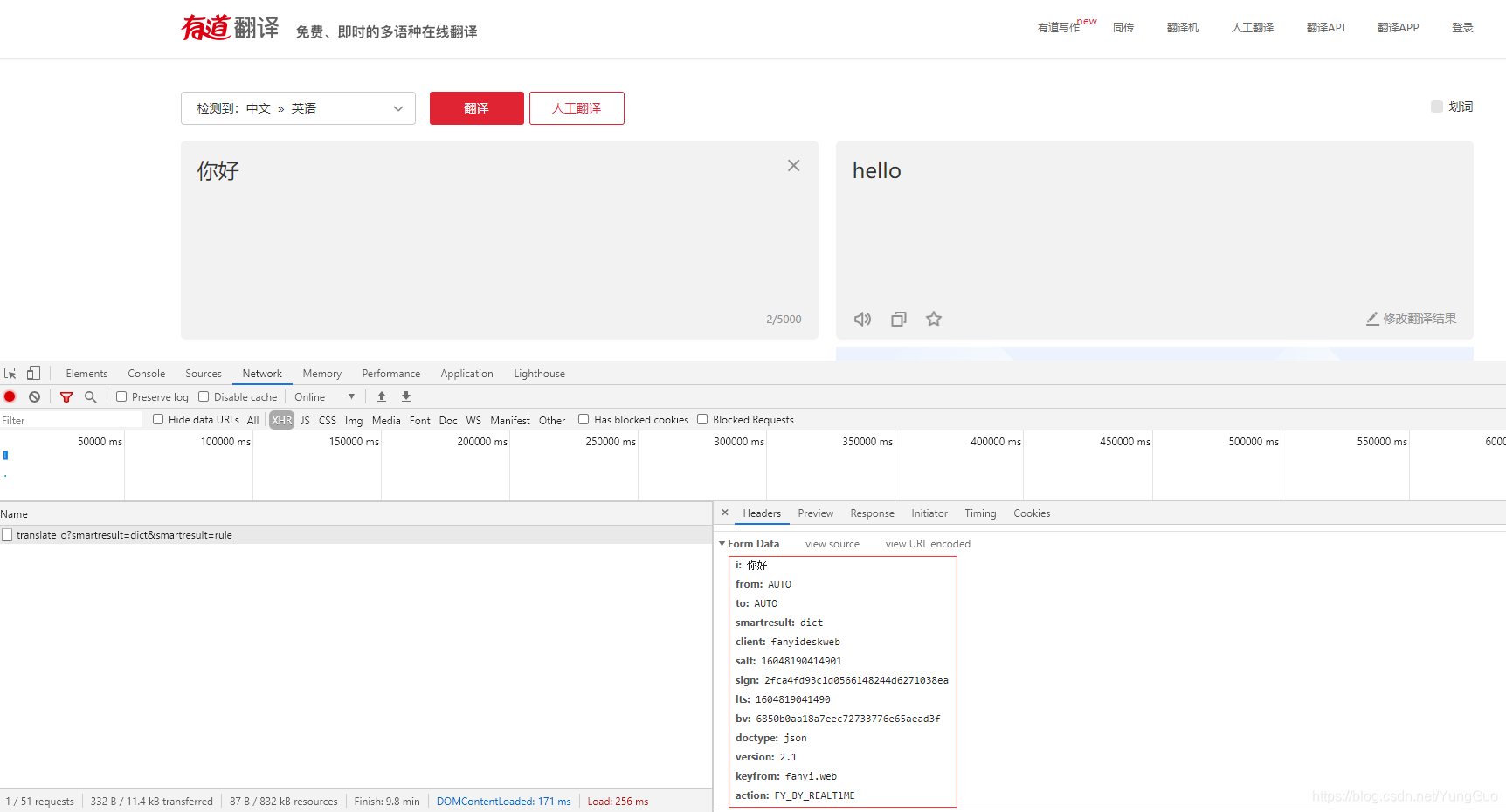 参数初步分析完成,那么固定值直接复制就行,接下来我们需要分析的就是变化的参数是怎么来的,变化的参数有salt、sign、lts、bv,先看看salt,要想知道这个参数,得先了解lts这个参数怎么来的,搜索到两个js文件和一个css文件,首先排除css,打开第一个js文件搜索lts并没有这个词,再打开第二个js文件发现代码中有两个lts,第一个是一个ajax请求中的data有lts这个词;
参数初步分析完成,那么固定值直接复制就行,接下来我们需要分析的就是变化的参数是怎么来的,变化的参数有salt、sign、lts、bv,先看看salt,要想知道这个参数,得先了解lts这个参数怎么来的,搜索到两个js文件和一个css文件,首先排除css,打开第一个js文件搜索lts并没有这个词,再打开第二个js文件发现代码中有两个lts,第一个是一个ajax请求中的data有lts这个词; 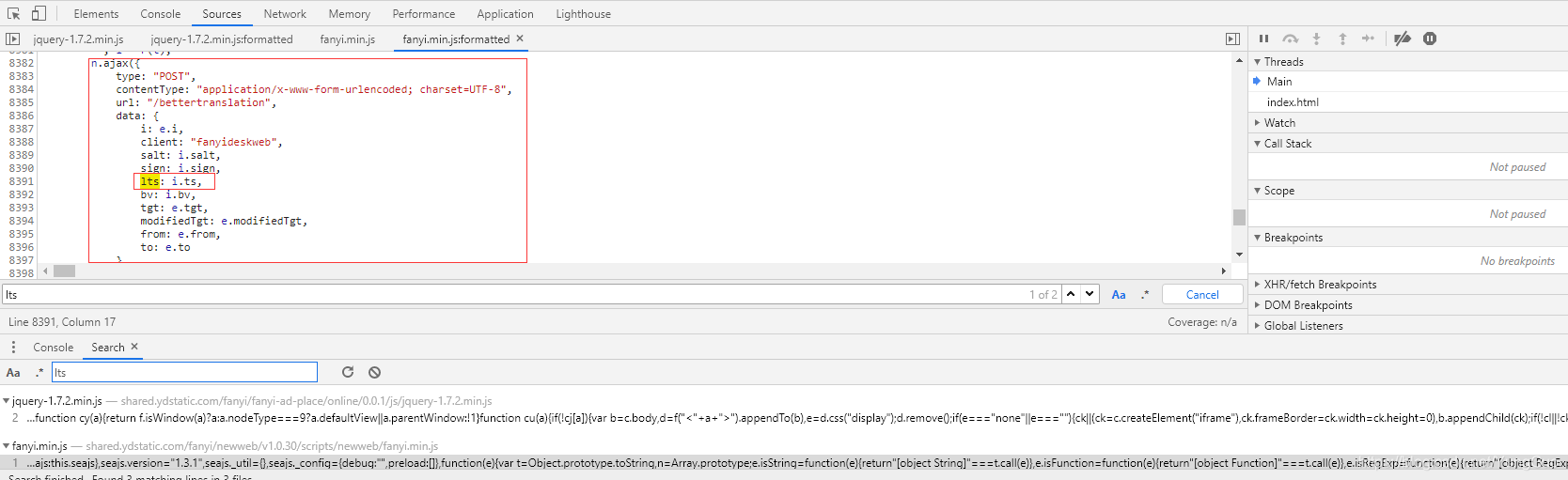 但请求的url和data参数貌似不对,应该不是这个,再看第二个lts,好像很眼熟!是不是有些固定参数和浏览器请求传的参数一模一样!在没有搜索到其他文件中有lts这个词的情况下,应该就是这个了;
但请求的url和data参数貌似不对,应该不是这个,再看第二个lts,好像很眼熟!是不是有些固定参数和浏览器请求传的参数一模一样!在没有搜索到其他文件中有lts这个词的情况下,应该就是这个了;  先断点看看这个参数怎么来的,结果发现salt、sign、lts、bv这几个参数在前面已经生成了,而生成方法就是generateSaltSign(n);
先断点看看这个参数怎么来的,结果发现salt、sign、lts、bv这几个参数在前面已经生成了,而生成方法就是generateSaltSign(n); 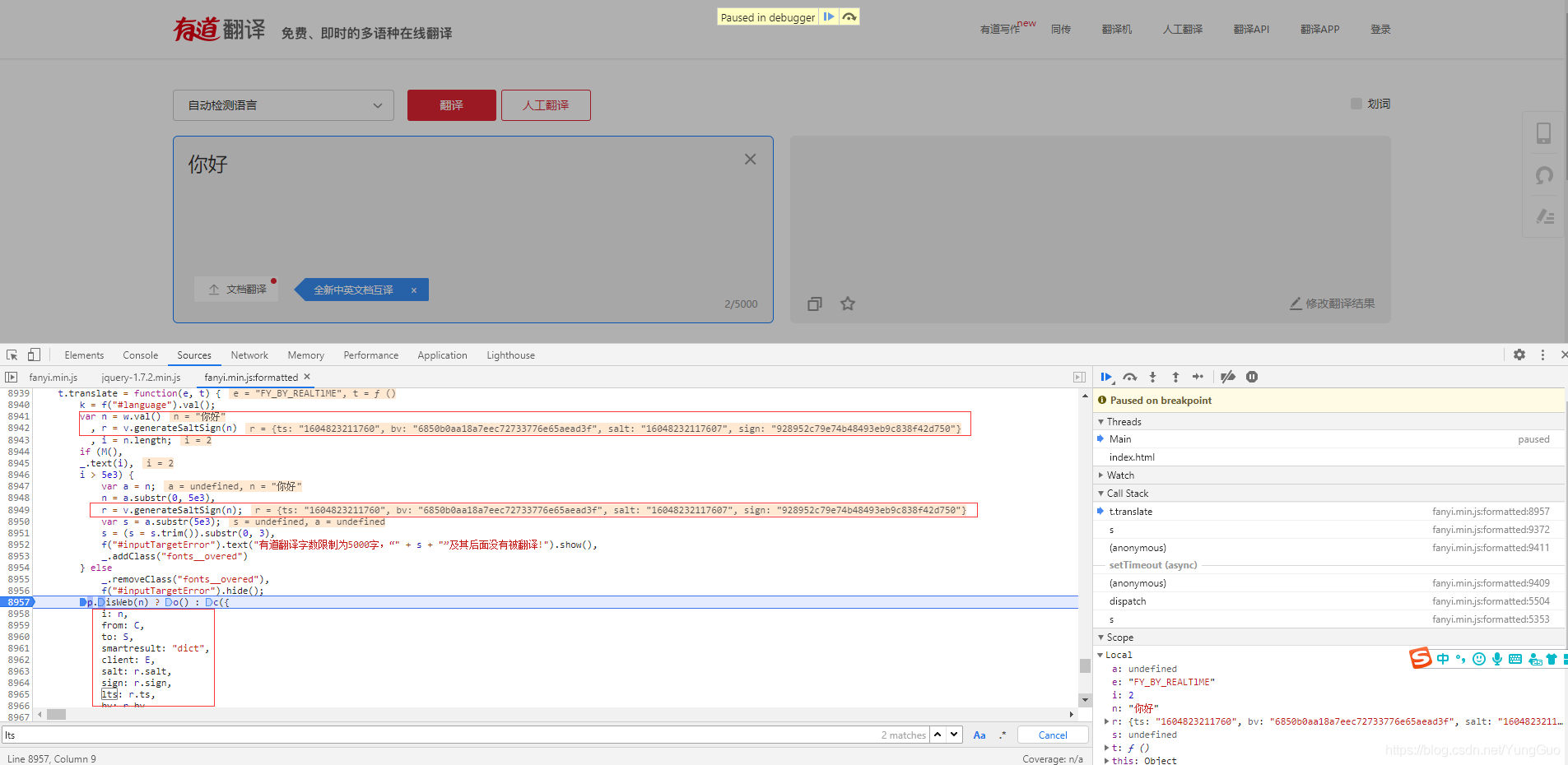 对这个方法断点,看到这个函数传了一个n其实就是翻译原文,并且指向了r(e)这个函数,我们点击这个函数跳过去看看;
对这个方法断点,看到这个函数传了一个n其实就是翻译原文,并且指向了r(e)这个函数,我们点击这个函数跳过去看看; 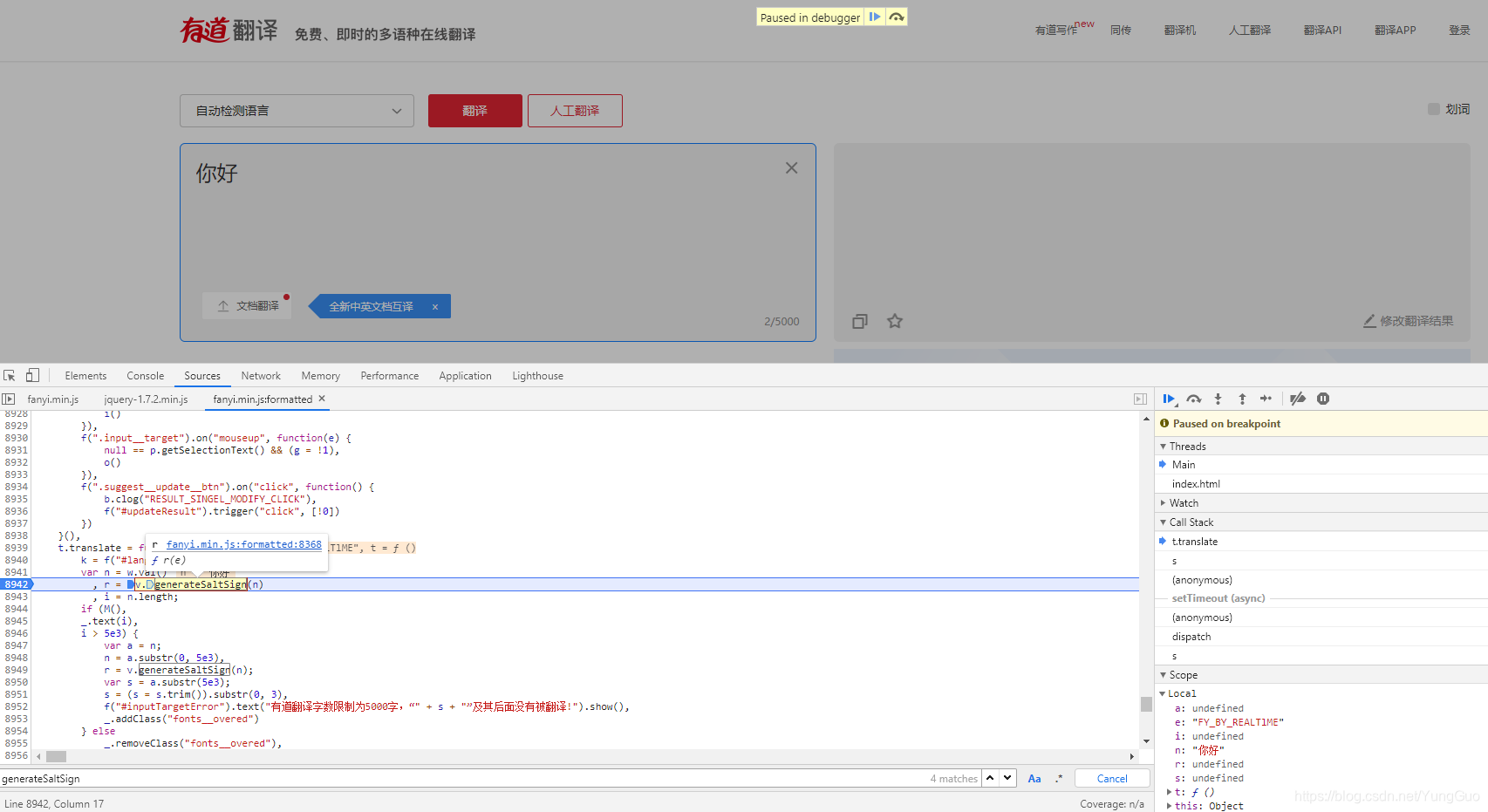 终于找到了这段生成几个参数的js代码,这个函数返回了四个参数,正是我们需要的,看看怎么生成的。首先函数r传入了一个e,e也就是之前的n(翻译原文),接着定义了t,r,i,从代码中看出t是对浏览器版本信息进行MD5加密,而bv就是t,所以就清楚了,为什么换浏览器的时候bv这个参数为什么会变化,而相同浏览器中并不会变化的原因;接着看r其实就是获取当前时间戳;i就是r+1位随机数;这也证实了之前的初步分析;继续解读sign,发现就是对一段字符串进行MD5加密,而字符串头部和尾部都是一段固定的字符串,中间的值刚刚也知道了就是翻译原文+salt,到此参数分析完成,开始写代码试试;
终于找到了这段生成几个参数的js代码,这个函数返回了四个参数,正是我们需要的,看看怎么生成的。首先函数r传入了一个e,e也就是之前的n(翻译原文),接着定义了t,r,i,从代码中看出t是对浏览器版本信息进行MD5加密,而bv就是t,所以就清楚了,为什么换浏览器的时候bv这个参数为什么会变化,而相同浏览器中并不会变化的原因;接着看r其实就是获取当前时间戳;i就是r+1位随机数;这也证实了之前的初步分析;继续解读sign,发现就是对一段字符串进行MD5加密,而字符串头部和尾部都是一段固定的字符串,中间的值刚刚也知道了就是翻译原文+salt,到此参数分析完成,开始写代码试试; 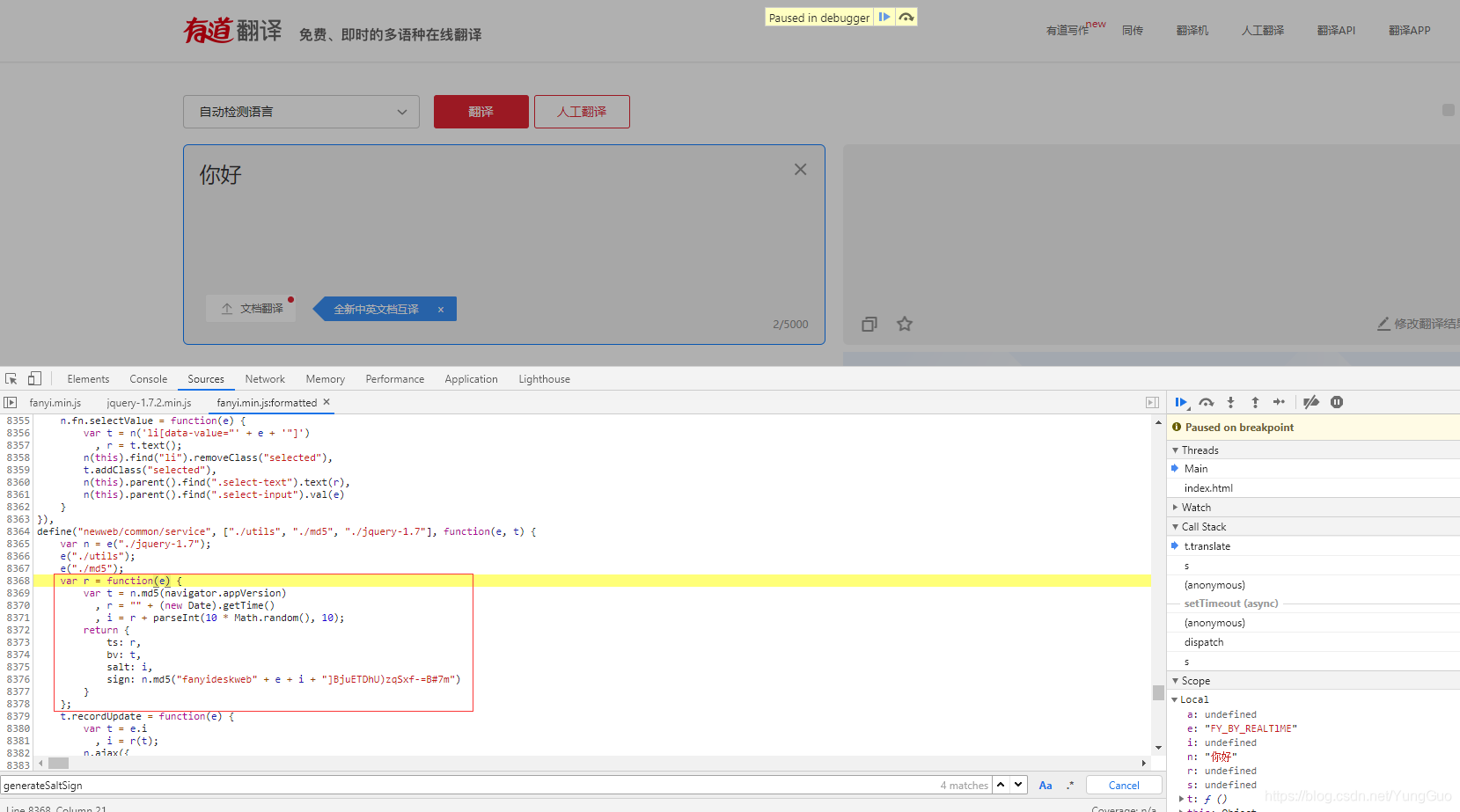 这里其实几个参数生成方法都比较简单,用python就可以做到,也就没必要用js代码去生成了 lts:时间戳,这个用time模块就行,因为js中时间戳是13位,而在python中要乘1000再取整
这里其实几个参数生成方法都比较简单,用python就可以做到,也就没必要用js代码去生成了 lts:时间戳,这个用time模块就行,因为js中时间戳是13位,而在python中要乘1000再取整【本文地址】
今日新闻 |
推荐新闻 |